


日期: 2024-09-21 作者: 固态硬盘
现今市面上究竟有多少款双核心手机?抛开黑莓惠普这些国内见得少的牌子不说,单是Android一家,同一个时期内就有数十家厂商上百款产品充斥市面,颇有当年大炼钢铁赶英超美的气势。大家都号称自己是双核心手机,这就带来了一个问题:究竟选哪个好呢?或者换个说法,都是“双核心”,它们之间难道就真的没有区别吗?为帮助大家更好的理解市面上双核处理器的异同,以便作出自己的选择,本文将从多个角度带领大家对目前市场中的双核产品做一次较为全面的了解。
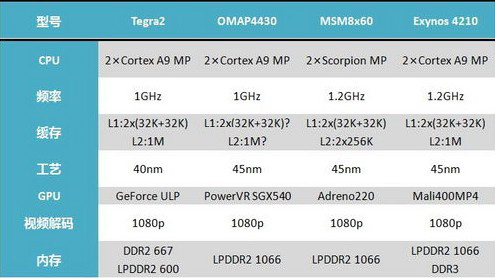
提到双核,可能大家首先想到的就是nVIDIA的Tegra 2。作为业界新人,nVIDIA必须要有一些别人不具备的优势,才能站稳脚跟,而nVIDIA选择的优势就是速度。Tegra 2是一款早在2010年1月就发布的双核手机处理器,为nVIDIA赚足了眼球,甚至俨然成了双核的代名词。

Tegra 2是nVIDIA在ARM SoC领域的第二款作品,由于第一款Tegra表现并不好,nVIDIA很早就开始设计Tegra 2,最终成为了移动消费领域第一款量产型双核ARM处理器,也正是靠这点,诸多厂家为了能赶在苹果之前推出双核产品,纷纷下单采购。因此大家便看到了今年年初MWC2011上双核设备的密集发布。这些双核机型成功从苹果手里抢走了“业界首款双核”的名头,直接引发苹果不得不在iPad2发布会上退而将A5称为第一款量产的双核处理器尽管大家都知道,当iPad2发布的时候,搭载Tegra 2的手机和平板已经开卖多时了。
Tegra 2的CPU部分采用的是双核ARM Cortex A9 MP,图形芯片(GPU)则是NV自有的GeForce ULP。它由TSMC以40nm工艺制造,预设工作频率为1GHz。相对于单核时代的Cortex A8而言,Cortex A9是ARM公司性能更强、功能更多,并且支持多核心配置的新核心。关于它的特性,在后面的文章中会详细解释,这里就先不详述了。在Tegra 2上,nVIDIA为每一个核心配备了32KB+32KB的一级缓存,以及累计1MB的二级缓存,但是在内存子系统上最高只支持到DDR2 667或LPDDR2 600,而且仅支持单通道内存。当然,随着现代手机对于多媒体功能,例如视频回放的需求,Tegra 2也引入了诸多格式最大1080p分辨率的硬件视频解码能力。
在nVIDIA宣布双核Tegra 2后仅仅一个月,另一家老牌半导体公司德州仪器也宣布了自己的OMAP4双核心平台,包含了OMAP4430、OMAP4460与2011年初发布的 OMAP4470三个型号。与Tegra 2相同,OMAP4也搭载了Cortex A9 MP架构的双核心,缓存资料不详,而GPU采用的则是PowerVR SGX540(不包括OMAP4470在内,下面的介绍仅指4430/4460)。可能有些读者能看出,这颗GPU与单核时代的三星蜂鸟处理器是一样的, 为此,德州仪器将这颗GPU的频率提升了50%,达到了300MHz,希望借此提升性能以拉开与单核处理器的差距。

OMAP4系列均采用45nm工艺制造,OMAP4430设计频率为1GHz,OMAP4460则设置为1.5GHz,因此能认为前者是针对手机平台设计的,而后者是针对平板机设计的。值得一提的是,与Tegra 2不同的是,OMAP4支持双通道内存,内部具备两个完全一样的内存控制器,这点在后面的文章中也能够正常的看到。至于内存规格,OMAP4430最高至支持 LPDDR2 1066,在频率上也要比Tegra 2高了几乎一倍。
另一家单核时代的主流供应商高通,则在2010年6月宣布了自家的双核产品规划,其中主频高达1.2GHz的MSM8x60是最吸引眼球的。这是第一款针对手机,且设计频率达到1.2GHz的 双核处理器,但与之前两家不同的是,高通在自家双核处理器上并没有采用类似于Cortex A9 MP的核心,而继续采用了与其单核处理器类似的Scorpion内核。

MSM8x60的内存支持能力与OMAP4430处于同一水平既LPDDR2 1066,但是对于是否支持双通道内存我们不得而知。GPU依然是高通自有的Adreno系列,当然型号升级到了更高级的Adreno220,高通号称可 以提供前一代两倍的性能。虽然高通不止一次提到自己将用28nm工艺生产ARM处理器,但MSM8x60采用的还是45nm工艺,一级缓存与Cortex A9一样,但二级缓存却只有512KB,比标准的Cortex A9 MP少了一半。多媒体支持级别与主流双核一样,也是1080p级别的视频回放。
与这些厂家的积极表现不同,作为三巨头之一三星在双核方案上似乎显得有些低调,一直到2010年9月才发布自家的双核平台,即大家熟知的代号猎户座的双核心处理器,量产型号为Exynos 4210。作为一款最晚发布的产品,猎户座在规格上也是最高的,不仅CPU配备了设计频率同样高达1.2GHz的双核Cortex A9 MP, GPU也使用了ARM自行设计的Mali400多核心GPU,而且不仅整合的是最高端的4核心设计,还大幅提高了工作频率三星官方宣称猎户座的3D填充率高达32亿像素每秒,这个数字要远远超过竞争。

视频解码是三星的传统优势,在猎户座身上这个优势依然得到了保持,对各种格式的硬件编解码都达到了1080p级别。至于内存,猎户座提供了独一无二的DDR3支持,这点是其它竞争对手所不具备的,而对于DDR2的支持也达到了最顶级的LPDDR2 1066,并且同样支持双通道。
好,这些就是即将上阵的选手了。下面我们会依次考量它们在诸多方面的表现,看看究竟哪个双核名副其实,哪个双核浪得虚名。
作为执行计算任务的最终单位,处理器核心本身的架构无疑是非常重要的一部分。从ARM11到Cortex A8,同样频率下性能的提升可以达到 2~5倍,这无疑就是核心的优势。在这四款双核处理器中,Tegra 2、OMAP4430、Exynos 4210均采用了Cortex A9 MP内核,而MSM8x60采用的则是Scorpion MP核心,它们之间有什么差距?要解释这个问题,我们先要回头看看Cortex A8和Cortex A9的区别。

在单核时代,Cortex A8架构是绝对的主流。作为ARM官方设计的产品,虽然Cortex A8和Cortex A9都基于ARM v7指令 集架构,但是它们之间依然有很多的不同点,其中最重要,也是用户最能感觉到的,是一项叫做乱序执行的功能。虽然Cortex A8和Cortex A9都支持同时执行两条指令,但是只有Cortex A9支持乱序执行能力,这个功能究竟是什么意思?
我们知道,计算机程序,都是由一条一条的指令组成的。这些指令有很多种功能,有的是把数据从一个地方复制到另一个地方,有的是做数学运算,有的负责判断某一个条件,有的负责从一处跳转到另一处。编译器会把所程序员写出的程序编译成一条一条顺序的指令,就像电器的使用指南一样,让处理器遵照它去做。为了方便理解,我们假设一个程序的内容是做一份考试卷,执行的过程是先做完选择题,再做完问答题;做选择题的条件是要有铅笔去涂答题卡,而做问答题的条件则是要有钢笔去写答题纸。
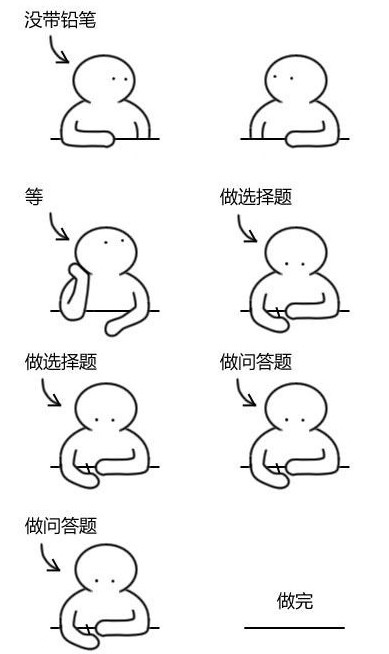
如果你忘了带铅笔,那么为了完成考卷,就必须要等到邻座的做完了选择题,你找他借来铅笔,才能继续自己的考卷,这样就耽误了时间。对于一颗标准处理器而言,很多时候都会遇到这类“没有带铅笔”的情况,比如需要访问的数据在内存里,这就需要处理器通知内存管理器,让内存管理器去把数据调入处理器,才能继续执行这一条指令。由于处理器内部的时钟延迟是纳秒级别,而内存的运行频率则有数十纳秒的延迟,两者之间差了许多倍,因此处理器一般需要消耗很长的等待时间,才能继续开始工作,最终的结果就是性能下降。
这时候,乱序执行就派上用场了。一个程序的指令都是有严格的逻辑顺序的,但是所谓的乱序执行,就可以打破这种原本的指令顺序,在逻辑允许的范围内以一种新的顺序去执行程序。如果继续用考试的例子,那就是这样:
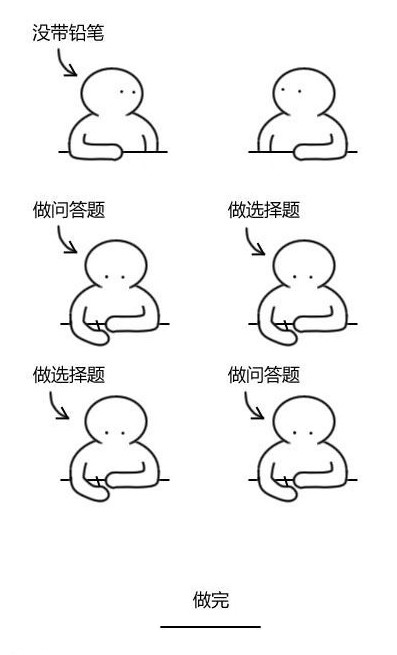
虽然编译器生成的考试指南告诉你,要先做完选择题,再去做问答题,但懂得变通的人会在没有铅笔的时候先去做问答题,这样就节省了大量的时间。支持乱序执行的处理器也懂得这样去“变通”,在遇到需要等待的指令时,如果后面的指令并不需要等待这条指令的结果,那么就可以先跳过这条指令,去执行后面的指令,大大节约等待时间,提升程序性能。当然,乱序执行并不是没有条件的,它要求被乱序的指令之间不存在严格的相关性。例如假设问答题里需要选择题的结果, 那么你就不能跳过选择题去做问答题,只能老老实实去等邻座的铅笔了。
那么回头来看看Scorpion核心。这个核心是高通在单核时代设计出来的,虽然也是基于ARM v7指令集架构,但在具体设计上属于高通自己的实现,与Cortex A8相比有很多区别,其中最重要的就是高通为Scorpion核心引入了部分的乱序执行能力。所谓部分的,就是说在某些特定指令序列下,Scorpion可以实现乱序的效果,Cortex A8则不行。在单核时代正是由于这点,高通的处理器核心在很多测试中的表现都要稍好于Cortex A8,但是当双核时代来临后,大家都升级到了支持完整的乱序执行的Cortex A9核心,而高通则依然沿用老旧的Scorpion核心,当年的优势就成为了现在的劣势。
不仅如此,在纯执行能力上,Scorpion面对Cortex A9也处于劣势。根据高通提供的数据,同样在1000MHz的频率 下,Cortex A8的执行能力为2000DMIPS(可以简单认为是每1周期执行两条指令),Scorpion比它要高一些,为2100DMIPS, 但是Cortex A9则高达2500DMIPS,领先Scorpion接近20%。虽然高通试图通过超频20%的方式弥补这个差距,但是在单线程性能 上,还是被竞争对手甩开了不小的距离,毕竟乱序执行的能力在很多应用中可以获得的性能提升远远不是这200MHz的频率可以弥补的,而且更高的频率也会抵消Scorpion核心在省电上的特点。这点在后面的测试里也可以看出来。
当然,Scorpion核心也不是没有自己的优势。作为高通自行设计的核心实现,它在一些方面有着超出ARM官方Cortex A系列的地方,例如它的二级缓存是直接连在两颗CPU上,而不是通过AXI总线共享的,在带宽和延迟上有着自己的优势。但是整体而言,Scorpion作为上一代核心,在新一代Cortex A9双核的面前还是显得比较孱弱的。
可能多处理器架构这个词对于不少读者而言都是很陌生的,很多人可能从来都没注意到过这方面的东西。所谓多处理器架构,就是说多颗处理器以何种模式共同运行,以怎样的方式合作执行程序。在PC领域,这个概念并不重要,因为大家看到的多处理器(多核心处理器也可以看作制作在一个芯片上的多处理器),在逻辑架构上都是一样的,那就是同步多处理器,英文为Synchronous Multi-Processors,缩写为SMP(不是对称多处理器的那个SMP)。但是在多处理器体系刚刚出现的阶段,曾经也有过很多不同的逻辑架构, 而在目前的手机市场上就恰恰存在着不采用SMP架构的多处理器,那就是高通的MSM8x60。
与SMP不同,高通所采用的架构名为ASMP,即异步多处理器架构。所谓同步和异步,差距并不是简单的两个字,在具体实现上的区别非常大。但是在此我们并不需要了解它们之间学术上的区别,我们只从最粗略的角度来看一下这两种架构的工作方式。
所谓同步多处理器,顾名思义就是同步的,即多枚处理器运行在同样的时钟频率,共享同样的缓存数据,协同工作。简单来说,同步多处理器系统在工作的时 候,每当一个任务完成后,空闲的处理器会立刻寻找下一个新的任务,对于外部而言,这两颗处理器是一个整体,共同完成同一个工作。
而异步多处理器则更接近于若干个独立工作的处理器,它们之间可以运行在不同的频率下,每个处理器维护自己私有的缓存数据,最重要的是,它们之间会利用一种仲裁机制,以轮流工作的方式执行任务。它们更像是一些互不干扰的独立处理器,各自完成各自的事情,轮流执行不同的工作。
看到这儿,相信大家也看出来了,同步和异步最大的区别就在于轮流工作这四个字。具体而言,就是在同一时间,只有一颗处理器可以接受任务,另一颗不论是否繁忙,都不能接受新任务。可能光靠文字说明还不是那么生动,下面我们就来看几张图,了解一下相对于同步多处理器“谁空闲谁接单“的工作模式而言,这种轮流工作到底是怎样进行的,又会导致怎样的结果。
图中每一横行代表一个时钟周期,我们用红色的方块代表正在读取任务,绿色的方块代表正在执行任务,方块中的数字代表不同的任务,而空白代表着空闲状态。在第一张图里,我们假设任何任务只需要一个周期就可以执行完毕。
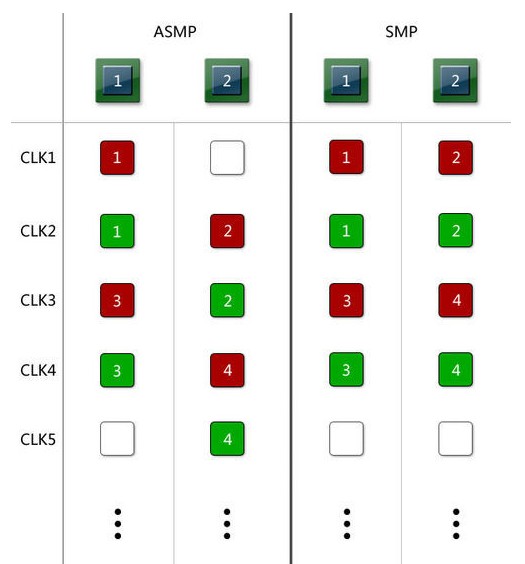
可以看到,在每一个周期内,异步多处理器架构最多只能有一个核心接受任务,而如果两个处理器都空闲,就会有一个消极怠工。如图所示,执行四条指令,异步多处理器用了5个周期,同步多处理器用了4个周期,异步多处理器慢了25%。
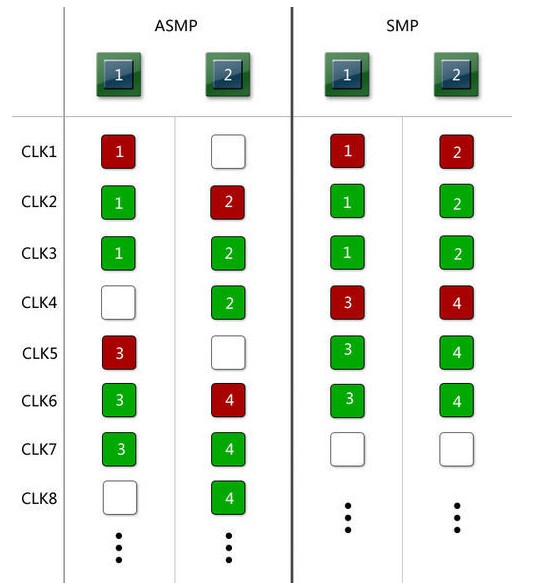
当指令执行长度为2周期时,新问题就出现了。由于ASMP架构中,处理器1只能在奇数周期接受任务,处理器2只能在偶数周期接受任务,虽然ASMP 中的处理器1在第3个周期的时候结束了当前的任务,但随之而来的第4个周期却只有处理器2可以接受任务。因为处理器2此时正忙于上一个任务,因此对于外部程序而言,在第4个周期上处理器会处于不可用状态,等到第5个周期到来以后才能继续接受新任务。因此SMP架构只需要6个周期就能完成的任务,ASMP却消耗了8个周期,慢了33%。
这就是为什么ASMP目前采用的越来越少的缘故。虽然ASMP存在着设计简单、结构清晰、耗电较低的优势,但是由于性能不足,在PC领域从来都没有成为过主流。而在移动领域,高通认为手机对于耗电的要求要大于性能,又希望可以在双核时代继续沿用单核时代的核心架构而不需要彻底重新研发,因此采用了ASMP架构。但是事实证明,高通在这点上可能有些耍小聪明之嫌,因为既然消费者决定购买双核,那么就一定是冲着性能去的,并且对功耗也已经做好了心理准备。
根据高通的官方数据,其1.2GHz的MSM8x60芯片组在满负荷工作的时候,仅处理器部分就要消耗大约1.2瓦特的功率,这相对于单核时代不到500毫瓦的功耗而言,也已经是非常高的数值了,这证明了不管怎么去省电,双核都依然是双核,既然如此,去追求双核应有的性能显然应该比如何去节省那么一点点的电更加重要。换一个方面说,性能足够强的话,系统可以以更短的时间完成任务,进而更多地进入低功耗的状态。高通通过ASMP也许节约了一定的耗电, 但是其最大33%的性能损失会导致系统多出33%的时间处于高功耗状态,消耗的功率可能抵消甚至反超节约的,让高通的如意算盘打空。
回到话题上来,可能有些读者会认为,单独来看,可能ASMP和SMP的差距也并不是那么巨大,在之前图中的极限状况下也就相差33%而已,在实际运行中的差距很难达到这个数字。但是不要忘记,之前的文章中我们讨论过乱序执行的重要性,那么如果我们将指令等待也引入到之前的图中,那么会发生什么情况呢?
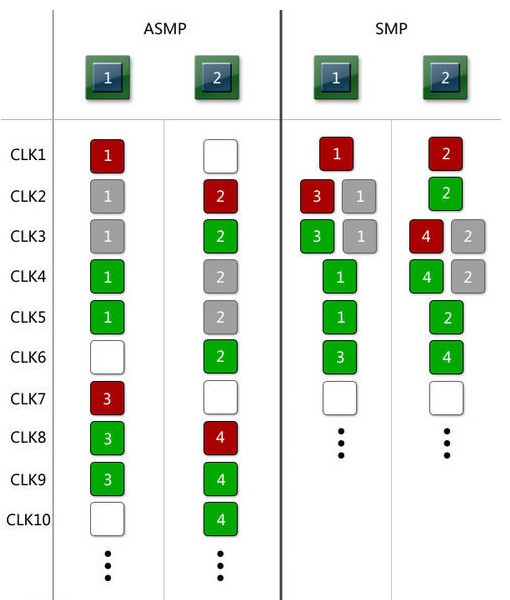
可以看到,一旦引入指令等待,将乱序执行与多核架构结合起来以后,不支持乱序执行的ASMP架构()需要10个周期才能完成的工作,支持乱序执行的SMP架构(Cortex A9 MP@其它主流双核方案)只需要6个周期,相对于支持乱序执行的SMP而言,不支持乱序执行的ASMP架构慢了66%。这就是MSM8x60面对其它双核Cortex A9的情况。虽然由于实际运行中指令的执行长度可能会更长,以至于减小轮流工作的影响,但由于Scorpion核心对乱序执行的支持并不完善,因此漫长的指令等待依然可能会导致高通的处理器浪费大量的时间,最终性能变慢。这点,我们也会在后续的测试中加以体现。
智能手机所采用的主芯片早已不能简单称之为处理器,而是一套复杂得多的系统,包含了处理器、显示加速芯片、内存控制器、视频解码核心、标准总线控制器等等,有些甚至还包含了数字信号处理器,它们被合起来称之为片上系统(SoC)。实际上一颗ARM SoC中,CPU所占据的硅片面积可能都不到总面积的二十分之一,而其中很大的一部分面积,都被各种各样的互联结构占用了。其实这也很好理解,片上系统就像一个大城市,如果交通不畅,整个城市的运行就会陷入瘫痪。在片上系统里有各种各样的总线,内部的、外部的,私有的、公用的。在这其中有一条最为重要的外部总线,连接着几乎所有的内部设备,那就是AXI。
更重要的是,内存控制器也是通过AXI连接到处理器,这就意味着不论你的内存颗粒或者内存控制器能够给大家提供多大的带宽,处理器能够获得的带宽都直接且仅取决于总线带宽。因此这个总线的宽度,决定了整个系统内部最大的内存带宽,同时也在某些情况下决定了诸如3D GPU这些对内存带宽需求巨大的模块的性能。正如城市的发展需要高速交通一样,随着片上系统的复杂化,内部互联的带宽也要求越来越大。
由于总线方面的信息不属于一般用户所理解的范畴,因此厂家往往也不会对此做出详细的说明,所以每一款芯片究竟总线宽度多少也是不容易查证的。这点上nVIDIA相对而言做的最好,因为他们曾经直接把AXI总线bit,类型为AMBA-3(这个参数在现在的网页上已经找不到了, 原因未知)。这一个数字是相当“惊悚”的,因为如果总线bit,那么意味着Tegra 2的内部总线级别的。因此nVIDIA在Tegra 2的内部,很可能采用了与标准ARM不同的总线配置方式,但是不论如何,Tegra 2的总线带宽都是难以置信的小,即便AXI频率达到300甚至400MHz,带宽最多也只能达到Cortex A8的水平。根据测试,Tegra 2的内存复制成绩大约只能达到1GB/s左右,这也基本符合其带宽的表现。
再来看看德州仪器的OMAP4430。与Tegra 2上的诸多猜测不同,德州仪器提供了OMAP4430的完整技术手册,因此各方面的资料非常容易获取。在OMAP4430中,互连结构分为若干级别和层次,但是就最主要的而言,是L3互联。德州仪器并没有采用ARM的AMBA AXI总线,而是在芯片内部的主互联上采用了Arteris公司的产品:

从图中可以看出,OMAP4430的L3互联宽度为128bit,是Tegra 2的四倍,因此即便工作频率为200MHz,总带宽也可以轻易达到3.2GB/s,远超于Cortex A8和Tegra 2。说实话,这才是双核Cortex A9 MP应有的水准。当然,由于各家SoC的内部体系都不太一样,在此也不能100%确定Tegra 2的实际情况。这点我们也会在后面的测试中继续研究。值得注意的是,OMAP4430的两个内存控制器在搭配LPDDR2 1066的时候可以提供的最大总带宽可以超过8GB/s,但由于总线带宽缘故,实际效果可能并不会有对应的提升,这也是ARM体系中一个比较头疼的问题之 一。
言归正传,下面继续来看看MSM8x60。一直以来,高通对于自家芯片的技术资料都守口如瓶。这维护了高通的知识产权,但是却苦了这样的人,因为根本无从查证芯片的详细参数,因此只能靠猜测了。一方面,MSM8x60基本上就是“双核版”的MSM8x55,另一方面在后续测试中也可以看出 MSM8x60在内存方面的性能并不是很突出,因此在此猜测MSM8x60的内部互联可能和单核时代一样,即64bit、200MHz,总带宽 1.6GB/s。各位读者如果有详细的信息,也不妨告知。
最后我们来看看Exynos 4210。三星和高通在这个方面有一定的相似性,也不肯公开提供芯片的技术手册。但是我们在三星自己的Exynos 4210宣传资料中还是可以发现一些端倪的。

在图中可以明显看出Exynos 4210同样支持双通道内存(DRAMC0与DRAMC1),而在之前的关键技术列表中,三星赫然写出了内存带宽6.4GB/s的数字。由于Exynos 4210是一颗几乎全以ARM公司产品打造的芯片,因此这个数字就意味着Exynos 4210的内部总线bit,只有这样才可以在200MHz的频率下达到6.4GB/s的内存带宽。这个数字已经远远的甩开了单核 Cortex A8、Tegra 2和MSM8x60,甚至比OMAP4430还要高出一倍,在双核时代的SoC中显然是傲视群雄的。
作为一台智能手机,多媒体功能是不可或缺的。早在15年前PC处理器巨头Intel就高瞻远瞩,为大家带来了一款叫Pentium MMX的产品,其最大的特色就是引入了名为多媒体扩展(Multi Media eXtension,MMX)的扩展指令集。
何谓多媒体扩展指令集?由于原理复杂坚涩,简单的打个比方:厂商们分析平时处理器干哪些事情最慢、又最经常用到,然后把这些最消耗时间的事情固化成电路,做成一个额外的部分,和处理器集成到一起。使用的时候,只通过一条指令,就能够访问和计算多组数据,把最消耗时间的事情尽快做完。在计算机词汇里,这种指令集叫做SIMD(Single Instruction Multiple Data,单指令多数据)指令集。
回到手机上,在ARM的世界里,由于日益增长的多媒体计需求,也出现了属于ARM自己的多媒体扩展指令集,它的名字叫做NEON。它可以帮助处理器加速任何格式视频的编解码,帮助显示芯片加速矢量数据的解析和打包,也可以让系统可以更快的处理几百万像素的图片。它所能带来的性能提升根据应用的不同,可以从比较明显的50%,到难以置信的8000%。
长期以来NEON指令集都是各种高端ARM SoC的标配,从ARM11到Cortex A8,基本上所有高端SoC都包含了对应版本的NEON指令集。而在Cortex A9时代,它更是像是理所应当一样,作为一个基本而不可或缺的功能,出现在各大厂商最高端SoC的蓝图中。
在德州仪器的OMAP4430和三星的Exynos 4210中,每一个Cortex A9核心都拥有自己专属的NEON协处理器,拥有专用的32个64位寄存器,以多通道操作的方式,加速系统的多媒体计算性能。而在MSM8x60中,高通甚至把它的NEON协处理器的位宽增加到了128bit,两倍于标准的ARM实现,让NEON协处理器可以一次性处理两倍的数据,带来更大的加速效果。
那么Tegra 2呢?令人感到意外的是,不知道出于何种原因或者考虑,Tegra 2没有搭配NEON协处理器。这对于一颗定位于顶级的双核SoC而言是十分不可理解的,因为NEON可以为几乎所有的多媒体过程提供明显的加速特性,而 nVIDIA却选择了放弃。可能有读者会说,Tegra 2有强大的显示芯片,不需要NEON的加速,但是不要忘记,显示芯片是不能完全独立处理所有的3D运算过程的,其中诸如数据解包和组合这种操作还是需要 CPU来完成,由于没有NEON,处理器必须要花费几倍于对手的时间才能“喂饱”显示核心,最终的结果就是性能无法发挥。
而在视频解码方面,Tegra 2也会因为不具备NEON协处理器而受到很大的影响。因为我们知道,Tegra 2虽然号称可以支持诸多格式的1080p全高清解码,但是它对视频的编码格式有着非常严格的要求,例如Tegra 2的视频解码核心只能硬件解码Main Profile的H.264视频,而对于其它的就只能靠处理器来进行软件解压。这时没有NEON协处理器的帮助,视频解压就很难高效的进行,最终导致Tegra 2的多媒体特性缩水。
也许nVIDIA是认为NEON协处理器的授权价格过于昂贵,或者可能因为规模太大而提升制造成本,而最终选择了放弃,但作为消费者而言,不具备NEON指令集的Tegra 2无疑会在多媒体方面的竞争中被对手远远甩开。好了,关于多媒体的比拼也要告一段落了,最后我们照例为每个处理器给出评分。
说到3D加速,这个概念哪怕放在区区5年前,对于手机而言都几乎是可有可无的。但是这几年随着iOS的崛起,与Android的飞速发展,3D加速一夜之间变成了高端手机必备的特性,甚至成为了整个手机用户体验的决定性因素。
而在新一代双核Cortex A9 MP SoC中,图形处理器(GPU)的竞争彻底进入了白热化阶段。从结构而言,四家的CPU好歹是一个蓝本(大家所采用的都是ARM v7架构),但四家的GPU却选择了四种完全不同的方案,这的确从另一方面印证了GPU的重要性与竞争的激烈性。
nVIDIA作为PC领域图形技术的领导者,在这方面是有着先天的巨大优势。Tegra 2所采用的GPU是nVIDIA自行研发的GeForce Ultra Low Power,缩写为GeForce ULP。它拥有四个顶点处理器,四个像素处理器,支持OpenGL ES 1.1/2.0、OpenVG等主流标准。在Tegra 2发布的时候,这枚GeForce ULP就是nVIDIA的宣传重点,因此消费者对于它的性能也有着极大的期待。
而作为曾经参与桌面竞争、当下专注嵌入式GPU的Imagination公司,自然不愿意让出嵌入式独立GPU市场的性能领导地位。在 OMAP4430上,我们看到的就是这家公司设计的PowerVR SGX540。这是一颗大家很熟悉的GPU,因为早在单核Cortex A8时代,三星就在代号蜂鸟的处理器中采用了这颗GPU,它强大的性能也让采用蜂鸟处理器的机型在单核时代傲视群雄。与GeForce ULP不同的是,PowerVR SGX540内并没有单独的顶点处理器或者像素处理器,而是包含了四组通用处理器。这种类似于桌面显示核心统一渲染器的设计结构可以让PowerVR GPU用最少的硬件获取最大的性能,从而节约成本和功耗。值得一提的是,也正是由于通用处理器的设计,PowerVR SGX540成为了当前唯一一颗支持OpenCL通用运算标准的GPU。

而在高通MSM8x60上,GPU则不出意外的是高通自行设计的Adreno。这是高通从前ATi公司收购而来并自行发展的图形架构,经过四代的发展,来到了最新的Adreno 220。相对于单核时代主流的Adreno 205,这颗GPU能够达到前者两倍的性能,从而得以参与到双核时代的GPU争夺战之中。当然,由于高通的“优良传统”,Adreno系列的架构一直不得而知,详细参数也很难查明,但是考虑到这是从ATi收购而来的架构,因此猜测应该也是基于分离的顶点处理器和像素处理器,只是各自的数量依然不甚明确。
而四大双核里最后登场的Exynos 4210,它在GPU上的选择也是最为有趣的,因为它所搭载的是由ARM官方设计的Mali400图形核心。这是一颗相对而言比较陌生的显示核心,因为这还是它第一次在顶级SoC中露面。
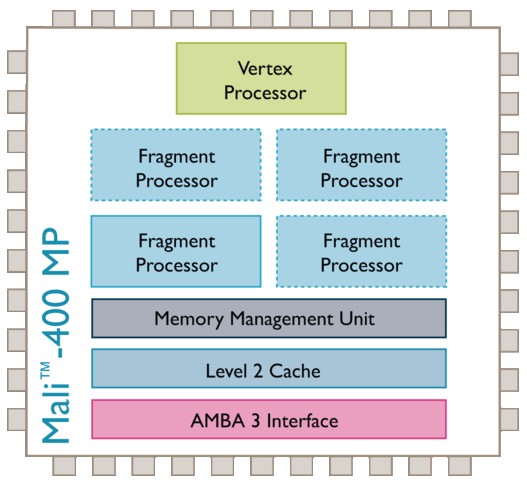
从架构上而言,Mali400也基于分离的顶点处理器与像素处理器,从逻辑角度而言要比PowerVR SGX540落后一些,也不支持OpenCL通用运算标准。但是这样的结构在目前的应用需求下,性能也未必会显得落后。标准的Mali400 GPU包含一组顶点处理器,而像素处理器则可以在一组到四组之间自由搭配,取决于你愿意支付多少授权费和制造成本。由于Exynos 4210是三星最顶级的ARM SoC,因此三星也当仁不让的选择了完整的四像素渲染器配置,即Mali400MP4。稍微岔开一下话题,虽然ARM宣称Mali400的这种设计是“多 核心”架构,但Mali400的“MP”与苹果A5处理器所采用的PowerVR SGX543MP2的多核是不一样的,后者才是真正的多核心,而前者只能称之为像素处理器可变而已。
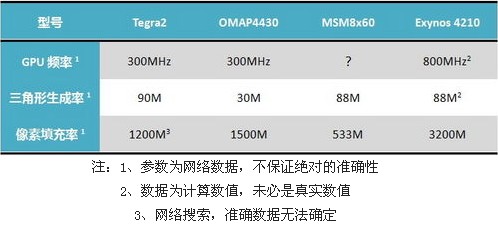
可以看到,在规格指标方面,Exynos 4210是遥遥领先的,而Tegra 2紧随其后。至于具体的性能表现,我们在后面的测试中将简单介绍。值得注意的是,上表中的参数未必是最终的实际性能,理论参数一般都会受到实际应用环境的强烈影响。
经过上述炫目的技术分析,相信我们大家都累了。下面就让我们从一些性能测试中一窥这几颗处理器在实际产品中的表现吧。首先介绍一下采用了这四颗芯片的实际产品。
需要注意的是,下面的测试并不是每一个产品都可能会有数据,也许某些测试只会有一部分的产品参与,而由于各个手机的分辨率不同,所以在3D测试里也 需要加以考虑,不能只看原始数据。有些测试因为太老,进入双核时代后大家的性能都受限于垂直同步而导致没有足够的差异性,例如Neocore,因此这里就不列成绩了。
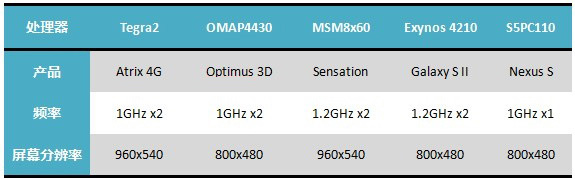
下面的测试对比就将在这五款机器中展开。首先让我们来看看Smartphone Benchmark 2011的结果。成绩来源为独立第三方手机性能测试网站Smartphone Benchmarks的官网首页,选择分数的标准为能确认的原始频率下最高的得分。
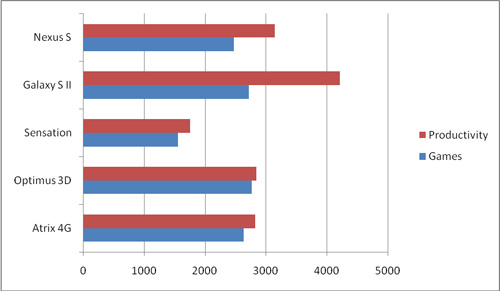
游戏,即GPU方面,可以看到Mali400MP4、SGX540、GeForce ULP得分相近。而生产力,即CPU方面,则是Exynos 4210一枝独秀。当然这也有一部分原因在于它的默认频率为1.2GHz。但是可以看到的是MSM8x60不论是GPU还是CPU,都被远远的甩在了后面,甚至还不如单核的S5PC110,其原因不外乎老旧的处理器核心与异步多核心架构。
然后我们来看看NenaMark 2.0。成绩来源依然是官网,所有型号的成绩取平均值:
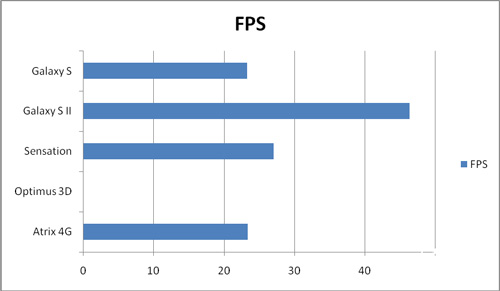
在这个测试中,Exynos 4210的成绩遥遥领先与所有对手,而Tegra 2也许是因为较低的内存带宽,导致成绩反而不如MSM8x60,甚至和上一代的单核也相去不多。当然,Galaxy S II的分辨率只有800x480,这里需要再一次强调。
下面再来看看另一款测试,名叫Electopia。这是一款游戏内建的测试,成绩为论坛收集:
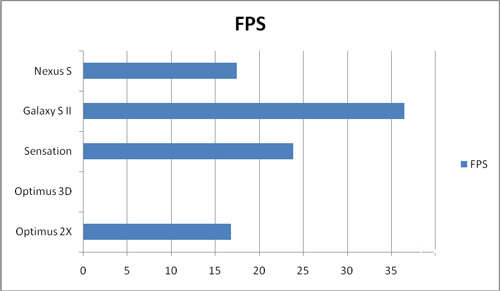
同样,Exynos 4210依然遥遥领先,而在这项测试中Tegra 2依然垫底,甚至不如上一代S5PC110,而且落后MSM8x60的比例比之前更大。
最后我们再来看看GLBenchmark的测试。这是一款以3D为主的测试软件,我们选取其中的Egypt场景作为对比,接着再来看看处理器性能。成绩来源为官网。由于此测试历史久远,参测机型固件版本众多,导致平均值参考意义不大,因此各自机型取最大值。
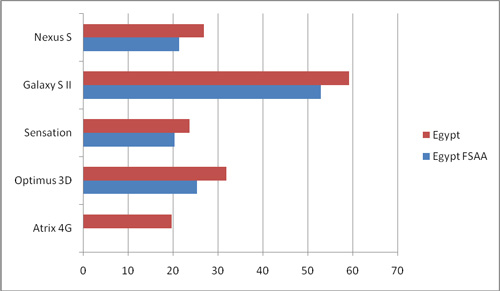
再一次,Exynos 4210取得了压倒性的优势,性能几乎是第二名的两倍。而MSM8x60的Adreno 220甚至还比不过上一代的PowerVR SGX540,不论是单核的S5PC110还是双核的OMAP4430。和上一个测试一样,Tegra 2再次垫底,原因可能也是因为带宽不足。
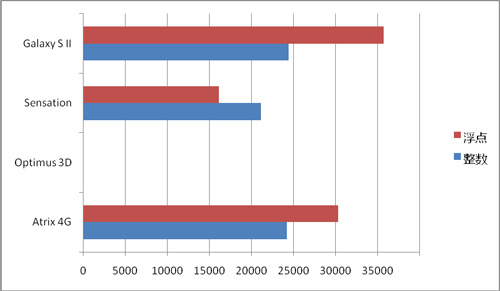
在这次测试中我们又一次看到了Cortex A9对Scorpion的压倒性优势。由于高通依然沿用了上一代的架构,因此不论是整数性能还是浮点性能都远不如Cortex A9。可惜的是OMAP4430没有测试成绩,不过应该和其余两款Cortex A9 MP相去不大。
最后再让我们来看一个不算测试的测试:AndroZip解压。成绩来源为网站测试,内容为1.2MB的压缩包解压,成绩为耗时,参与机型只有Galaxy S II与Sensation。
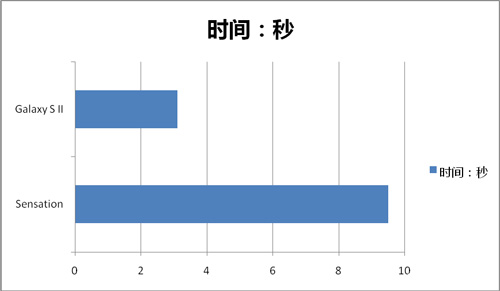
可以看到,同样的频率下,MSM8x60所花费的时间为Exynos 4210的300%多,这样的差距足以说明在某些应用下,架构的区别可以带来多大的差距。
看完了上面的测试,各位对这四大双核应该也能有一个概念了。总体而言,三星没有食言,Exynos 4210不论在任何方面,都是双核中最强的,领先第二名的程度都非常明显。而OMAP4430则靠着各方面稳定而平均的表现,成为了双核时代另外一个理想的选择。高通的MSM8x60在3D测试中体现出了一定的实力,但由于架构和核心原因,在牵涉到CPU性能的测试中均溃败给了所有对手,实际表现和单核并没有太大差别,认为追求双核性能的用户选择高通平台并不合适。
至于Tegra 2,作为世界上第一款双核心ARM A9处理器,我们只能说它光荣的完成了双核心的铺路石作用。由于NV太过节省成本,Tegra 2的内存带宽和多媒体指令集都未能完善,导致实际使用中的体验下降,最终得分和高通MSM8x60一起垫底。作为回顾,我们看看四款处理器都得到了多少颗星:
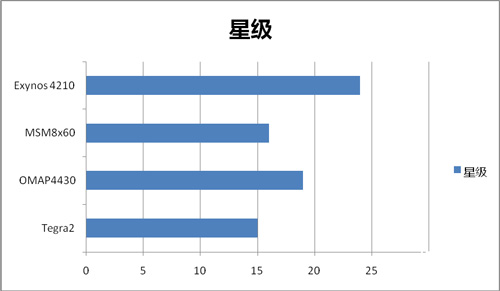
看完上述评测,也许很多人会觉得,为什么Tegra 2如此之差? nVIDIA果然还是这方面的菜鸟啊!如果这样想你就错了,因为在这些芯片的背后,还有一些重要的参数和取舍,之前的文章里我们并没有提到,那就是成本。
众所周知,芯片是从硅晶圆上切割出来的,一块300毫米的晶圆价格高达数十万美元。所以,就像切蛋糕一样,芯片面积越小,能切出来的芯片越多,成本自然也就越低了。
但是芯片的面积又取决于晶体管的数量,而晶体管的数量往往正比于性能,因此这是个取舍的过程。有必要注意一下的是高通的SoC因为内置基带处理器,相对于其他的SoC而言多出了几个模块,在考虑尺寸的时候需要注意一下。
网上查到的资料毕竟是粗略的,因此在此也不能保证绝对的准确性,请各位读者原谅。

作为对比,我们加入了Apple A5的数据。可以看到的是,虽然大家在参数上看差不多,但是面积方面相差却非常巨大,最小的Tegra 2核心面积甚至不到最大的Apple A5的一半,这意味着一片晶圆可以切割出的Tegra 2数量是A5的两倍以上,前者的成本也要大大低于后者。这都是厂商在设计芯片时的选择问题,到底时倾向于成本,还是倾向于性能,nVIDIA的选择显然是前者,而事实上也是如此。
对比苹果A5处理器我们会发现,单单是PowerVR SGX543MP2这一颗GPU,占据的芯片面积就几乎和整颗Tegra 2一样大。从这个角度而言,Tegra 2是成功的,因为它的GPU只用了对手不到八分之一的面积,就实现了几乎一半的性能,性能成本比无疑非常可观。
Tegra 2的OEM报价只需要15~25美元,而作为对比,上一代三星单核蜂鸟处理器的报价就已经达到了20美元,而双核时代的猎户座必然要贵很多,因为猎户座的核心面积也超过了Tegra 2的两倍。与价格相同,芯片面积越多、晶体管规模越大,满载时的功耗就也更大,因此Tegra 2在满载时的功耗有可能会比其他产品小。但问题是Tegra 2为了降低成本而去掉的特性太多、砍掉的性能太狠,很多时候反而得不偿失。丧失了成本与性能的平衡点,这也许才是nVIDIA犯下的最大的错误。
而三星则试图追求最大的内部互联带宽,我们也看到了,Exynos 4210可能是唯一一颗采用了256bit内部总线的SoC,而这个总线无疑也会占据相当大的硅片面积。而OMAP4430在各方面都较为平庸,因此芯片 面积也居于中等水平。可以说,厂家的侧重各有不同,导致最终产品之间的巨大差异,在这方面,德州仪器做的无疑是最好的,不论是成本、功耗还是性能都是一个很适中的档次,而Exynos 4210与Apple A5则走在了性能的极端,实际上可以说忽略了成本与功耗的表现。而最悲剧的依然是Tegra 2,nVIDIA片面追求低成本,导致性能方面惨不忍睹,这可能是nVIDIA在Tegra 2上需要学到的最大的教训。
好了,我们的文章至此也要结束了,如果你仔细阅读了我们的内容,相信你对市面上的各种双核心手机已经心中有数。双核大战,四大巨头,看起来很热闹,不是吗?但是在这片繁荣的背后,看到的是我们被透支的未来。
2007年,手机硬件升级大战第一把火由苹果燃起,紧随其后的Android的发展,把拼硬件之风成功发扬光大。而到了2011年,以nVIDIA为代表的PC企业的介入,更是把拼硬件的速度与力度提到了史无前例的地步,一代手机的生命周期往往只有12个月。
性能在翻倍,功能在增加,随之而来的却是越来越高的功耗,越来越大的发热,一天比一天重的电池,和一天比一天短的续航。根据高通提供的数据,工作在1.2GHz的MSM8x60,仅CPU部分的功耗竟高达1.2瓦,再加上显示核心,功耗更是不可想象。
其实,哪怕我们把时间推回到短短5年前的ARM11时代,续航、功耗,都不是用户需要去关心的问题,但自从进入双核时代,高配置手机的续航时间就已经开始以半天甚至小时作为单位,而满载时外壳高达50度的巨大发热,也在不断考验着用户的忍耐极限。每个人都应该问自己,这真是我们需要的手机吗?
相信有很多人会说不是。但厂家可不会理会这点。因为硬件升级是一场军备竞赛,谁也不愿意落在后面。于是,我们在NV的路线年底推出的四核心芯片,看到了28纳米将首先用于制造ARM芯片。
再过半年多,新一代的Cortex A15又将扛起新一轮拼硬件的大旗,而频率会直冲2GHz。在这样恐怖的速度背后,我们还有多少资本可以支撑现在的发展速度?半导体工艺是有物理极限的,业界迄今为止都对线纳米以下的超大规模集成电路束手无策,移动计算市场这辆由厂家和消费的人共同催动的火车,已经能看到近在咫尺的悬崖。

几年后,当人们手里拿着的都是装着散热器、风扇呼呼响的“手机”,终于意识到这样不行的时候,却发现已经无路可退;当人们终于开始怀念聊天看书发短信,充电一次管一周的手机时,却发现这样做的企业已经倒在了硬件大战滚滚洪流之中,这才是移动产业的悲剧。
 官方微信:hengwin
官方微信:hengwin